Prédire les chiffres de vente grâce à l’I.A ?
Chaque année, les éditeurs reçoivent un très grand nombre de manuscrits, dont seulement 2 % seront publiés en moyenne, parmi lesquels 1 % deviendront des bestsellers. L’étape de lecture et de tri qui suit la réception de ces milliers de manuscrits représente pourtant une charge de travail élevée, et il arrive aux meilleures maisons d’édition de passer à côté de manuscrits susceptibles de devenir de véritables succès de vente : c’est ce qu’on appelle le syndrome Harry Potter. Pour assister les éditeurs dans cette tâche cruciale, la startup allemande QualiFiction a développé et commercialisé un logiciel basé sur l’intelligence artificielle, destiné à identifier les meilleurs textes. À l’occasion d’une conférence qui s’est tenue à la Foire du Livre de Francfort en octobre dernier, nous avons rencontré la directrice de cette startup.

LiSA, le logiciel développé par QualiFiction, s’appuie sur l’immense puissance de calcul et les algorithmes de l’intelligence artificielle afin de déterminer la valeur d’un manuscrit pour une maison d’édition spécifique. Gesa Schöning, qui a travaillé pendant un temps dans la librairie familiale, ne nie évidemment pas la dimension humaine inhérente au métier d’éditeur. Elle estime cependant que les problèmes économiques rencontrés par le secteur du livre exigent une remise en question de la manière de travailler, qui doit selon elle se centrer bien davantage sur les besoins des lecteurs.
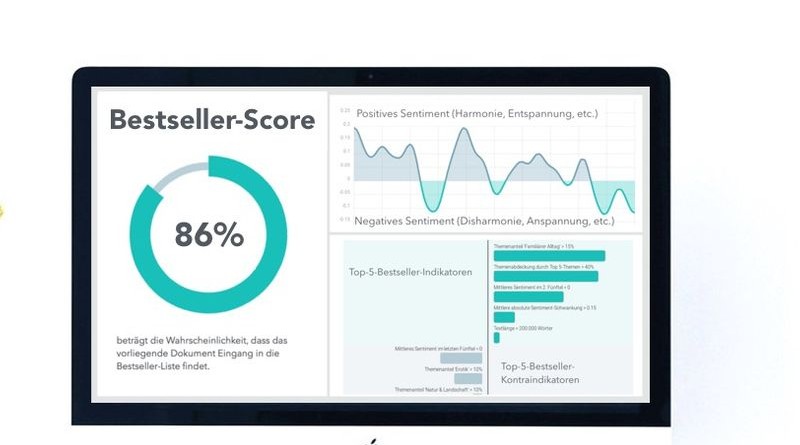
Pour mettre au point ce logiciel, elle s’est associée au mathématicien Ralf Winkler, spécialisé en science des données ; ils ont déterminé ensemble les méthodes mathématiques adéquates à ce genre d’analyse. Si le programme, très complexe, n’est pas encore infaillible, il fournit des informations très utiles aux éditeurs ; après une analyse qui dure moins d’une minute, il assigne en effet aux manuscrits un « Bestseller Score » et fournit à l’éditeur un rapport complet sur différents paramètres et la susceptibilité que toutes les caractéristiques ainsi identifiées plaisent au lecteur :
- Les sujets ;
- Le genre ;
- L’intrigue ;
- Le niveau de suspense ;
- Le niveau de réflexion ;
- Les éléments stylistiques (longueur et complexité des phrases, diversité du vocabulaire) ;
- Analyse des personnages principaux (interaction, mode de communication, sexe) ;
- Analyse des personnages secondaires ;
- La présence de scènes de la vie quotidienne ;
- Le niveau d’innovation par rapport au reste du catalogue.
Les paramètres d’analyse sont bien sûr adaptés aux besoins de la maison d’édition, le profil du public cible jouant un rôle important : si l’éditeur publie des romances, tous les thrillers seront immédiatement écartés.
Le logiciel se penche également sur la structure et la dramaturgie, les représentant sous forme de courbe, de même qu’il signale s’il y a une résolution à la fin du livre. Le rapport effectue alors une comparaison en contexte avec d’autres titres (le catalogue de l’éditeur, par exemple, ou des bestsellers similaires). Il informe aussi sur les modifications des sentiments ressentis (ou de l’atmosphère) au fil du livre, et leur fréquence.
En guise de note finale, un algorithme attribue des points à ces différents critères. Le résultat obtenu ne donne pas une idée de la valeur intellectuelle du livre et s’il s’agit de « bonne littérature », mais permet de prédire un éventuel succès.
Le logiciel a subi un apprentissage automatique à partir d’une base de titres publiés et des chiffres de vente qu’ils ont réalisé. La machine a ainsi mis en relief des schémas reconnus. Cet apprentissage machine (et le feedback reçu) permet d’utiliser le logiciel pour des textes inconnus.
![]()
Gesa Schöning le répète, il ne s’agit pas de remplacer l’éditeur, mais de fournir un travail en amont et de lui signaler les manuscrits potentiellement intéressants, pertinents et susceptibles de fonctionner.
Le logiciel peut également procéder à un pronostic de tirage, en fonction de la disponibilité (papier ou numérique) et de la date de publication. Pour l’instant, la proportion d’erreurs monte à 10 %, une marge qui s’explique aussi par le fait que le texte ne décide pas seul de son succès. Le logiciel ne donne qu’une moyenne, une zone de succès, mais des facteurs peuvent faire varier les résultats, notamment le niveau de notoriété de l’auteur. Il permet cependant de réduire les coûts de stockage et d’analyser la situation sur le marché.
Petit bémol : pour l’instant, le logiciel ne fonctionne pas pour les ouvrages non fictionnels qui possèdent des caractéristiques évidemment différentes : la diversité y est beaucoup plus importante, rendant l’analyse plus difficile. L’achat comprend des frais uniques au moment de l’installation et de l’adaptation à la maison d’édition, ainsi qu’un abonnement mensuel à trois chiffres. Aujourd’hui disponible en allemand, il le sera bientôt en anglais.
Retrouvez Lettres Numériques sur Twitter, Facebook et LinkedIn.
— Elisabeth Mol



