Rendre Wikipédia plus fiable, la nouvelle ambition d’Internet Archive
Lors de sa célébration annuelle fin octobre, la grande plateforme d’archivage et bibliothèque numérique Internet Archive a annoncé un nouveau projet visant à améliorer l’accès au savoir pour tous. En effet, celle-ci s’associe à l’encyclopédie collective Wikipédia. Le but de cette collaboration est l’enrichissement des références bibliographiques présentes dans les articles en y associant le contenu digital approprié, issu de la base de données d’œuvres numérisées par Internet Archive.
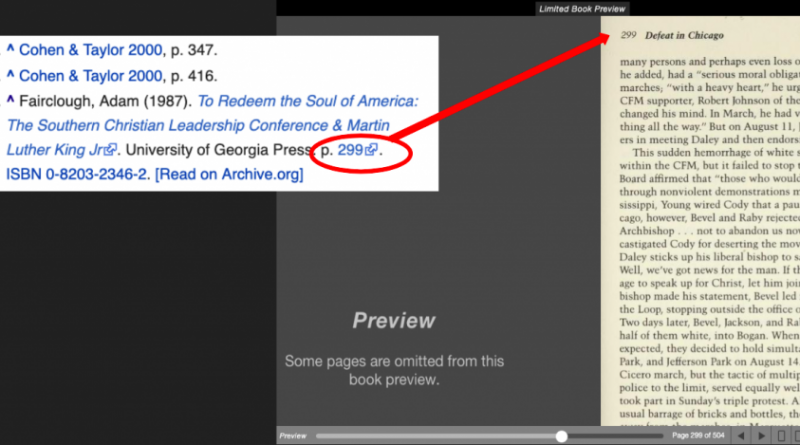
Un lien direct entre la citation sur Wikipédia et le livre numérisé
Plus de 130 000 références bibliographiques sur Wikipédia ont ainsi été reliées à 50 000 livres numériques disponibles dans la bibliothèque d’Internet Archive. Pour l’instant, seules les citations issues de livres s’appliquent à ce projet, bien que le fondateur Brewster Kahle n’exclue pas l’incorporation éventuelle de périodiques scientifiques en temps voulu. Ce nouvel outil de référencement est également limité à des pages en anglais, arabe et grec.
La collaboration avec Internet Archive répond au problème de la fragilité des citations sur Wikipédia, parfois basées sur des livres anciens dont il est difficile de se procurer une copie pour vérifier l’exactitude des informations. Un certain nombre de liens en notes de bas de page renvoient par ailleurs vers Google Books, conduisant à des pages blanches ou des petits extraits.
Ce système permet donc aux chercheurs d’avoir un accès facilité à un aperçu numérique de données citées sur Wikipédia, restituées dans leur contexte originel. Les lecteurs peuvent ainsi accéder à deux pages de consultation, avec la possibilité d’emprunter une copie numérique du bouquin par la méthode Controlled Digital Lending (CDL).
La vérifiabilité pour rendre Wikipédia plus légitime
Le partenariat entre Wikipédia et Internet Archive veut offrir de nouvelles opportunités aux étudiants, scientifiques, lecteurs (parmi d’autres) de consulter des sources rapidement identifiables et justes. Cette initiative permet également de promouvoir une utilisation plus légitime de Wikipédia en tant que point de départ dans le développement du savoir.
Pour rappel, ce n’est pas la première fois qu’Internet Archive organise des interventions sur les pages de Wikipédia. L’organisation a notamment lancé Wayback Machine en 2001, une plateforme recensant du contenu digital, et comprenant quelque 391 milliards de pages web archivées.
Afin de répondre à la politique de vérifiabilité des informations chère à Wikipédia, Internet Archive a ensuite créé InternetArchiveBot, un outil permettant de détecter les liens cassés pour les remplacer avec des versions archivées sur Wayback Machine. Depuis 2015, 13 millions de liens défectueux ont ainsi été remplacés avec succès sur Wikipédia.
Selon Mark Graham, directeur du service Wayback Machine, l’ajout de liens aux références bibliographiques est un processus similaire à celui décrit ci-dessus, mais plus complexe. En effet, si la référence a été introduite correctement, et que le bouquin dispose d’un code ISBN, il sera plus aisé de lier le contenu Wikipédia à sa version originale numérisée. Cependant, la majorité des références sur Wikipédia ne sont pas écrites dans un format correct (par exemple, elles ne précisent pas sur quelle page se situe l’information), soit certains livres ne disposent pas d’un code ISBN, soit le contenu d’une œuvre peut varier selon les différentes éditions.
Un projet ambitieux
Cette démarche s’inscrit dans un contexte plus ambitieux, dans la mesure où Internet Archive désire lier chaque référence bibliographique pour que les utilisateurs puissent consulter et emprunter tout livre cité par Wikipédia.
Enfin, le but ultime est la numérisation de la totalité des livres publiés, à l’instar de Google et d’autres organismes attelés à la même tâche. Selon Brewster Khale, il est impératif de transmettre les siècles de connaissances accumulées dans des vieux livres aux générations habituées à l’apprentissage numérique. Internet Archive espère ainsi « connecter les lecteurs aux livres en tissant ces livres dans la matière de la Toile elle-même, en commençant par Wikipédia ».
À ce jour, Internet Archive dispose d’une collection de 3,8 millions de bouquins, et continue sa démarche de numérisation à un rythme de 1 000 livres par jour.
Ailleurs sur Lettres Numériques :
- Rencontre avec Philippe Gambette, acteur du développement des bases de données littéraires en ligne et de l’analyse de texte
- La Journée du Domaine public à l’ère numérique
- Écrire à plusieurs ? Simple comme… écrire sur Wikipedia !
Retrouvez Lettres Numériques sur Twitter, Facebook et LinkedIn.
— Karolina Parzonko



